Hassy Veldstra
Building Artillery.io • Interested in OSS, SRE, product design, SaaS • always up for coffee ☕ • h@veldstra.org • @hveldstra
A tale of debugging with git-bisect
Houston, we have a problem
One day after upgrading a bunch of Artillery’s dependencies, a test case
that used to pass started failing with an allocation failure, i.e. the Node.js process was running out of memory (the test is question: large_payloads.json, which stress tests the HTTP engine with large payloads). It was easy enough to pin down the source of the problem to upgrading Request.js from v2.58.0 to v2.68.0. While downgrading to 2.58.0 was a fine temporary solution, the regression really needed to be found and fixed. Small problem - exactly 100 commits between 2.58.0 and 2.68.0 and very little will to look through every one of them to find where the regression was introduced.
Enter git-bisect
This situation is of course exactly what we have git-bisect (and binary search) for:
In a nutshell, instead of running the failing test on every commit starting with the one right after 2.58.0 in succession to try to find the bad one, which in theory could mean running the test 100 times, with git-bisect / binary search we only need to run it a maximum of 7 times - and git-bisect will automate checking out the right commit for us.
For the Visual Thinkers Like Myself
This is what the situation looks like.
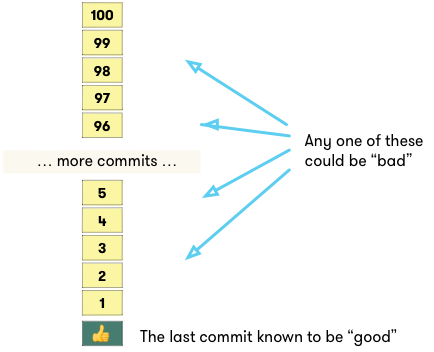
With binary search, instead of checking out every commit in sequence, we start by testing commit #50. If it’s “bad”, we can discard commits 51-100:
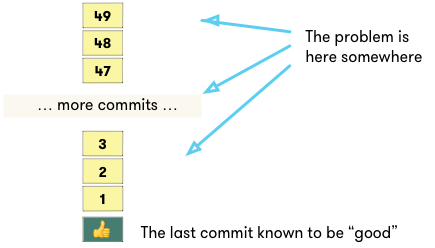
We repeat the process with commit #25 next which allows us to discard half of these commits again, and on and on until we find the culprit.
Finding the Bad Commit With git-bisect
We need two things to start:
- A test case that demonstrates the regression (or absence thereof)
- The commit hash of the last known good commit
And off we go:
git bisect start- start the searchgit bisect bad- the current (most recent) commit is badgit bisect good 422904fff031c3c2f39c569fc3bc2cbb6c9691cd- that was the last commit known to be good

We can see that git-bisect drops us into the commit that sits halfway between the bad and the good commit so that we can run our test on it. Which is exactly what we’ll do:
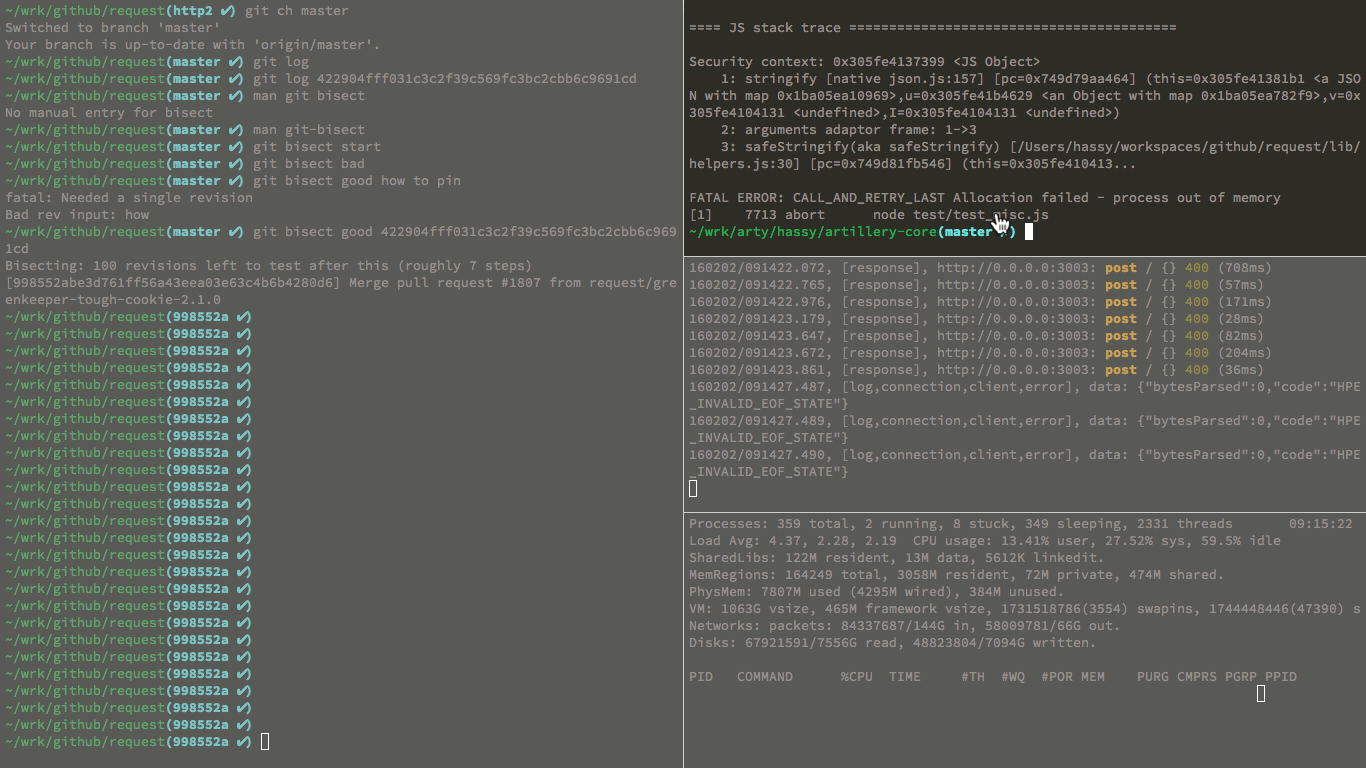
The most relevant part here is the upper-right window - the Node process ran out of memory and died, hence we’ll run:
git bisect bad
And let git pick another commit to test for us:

And we try again and again, until we hit gold:

That’s the commit we’re after.
Let’s Take A Look
This is the diff of the commit in question:
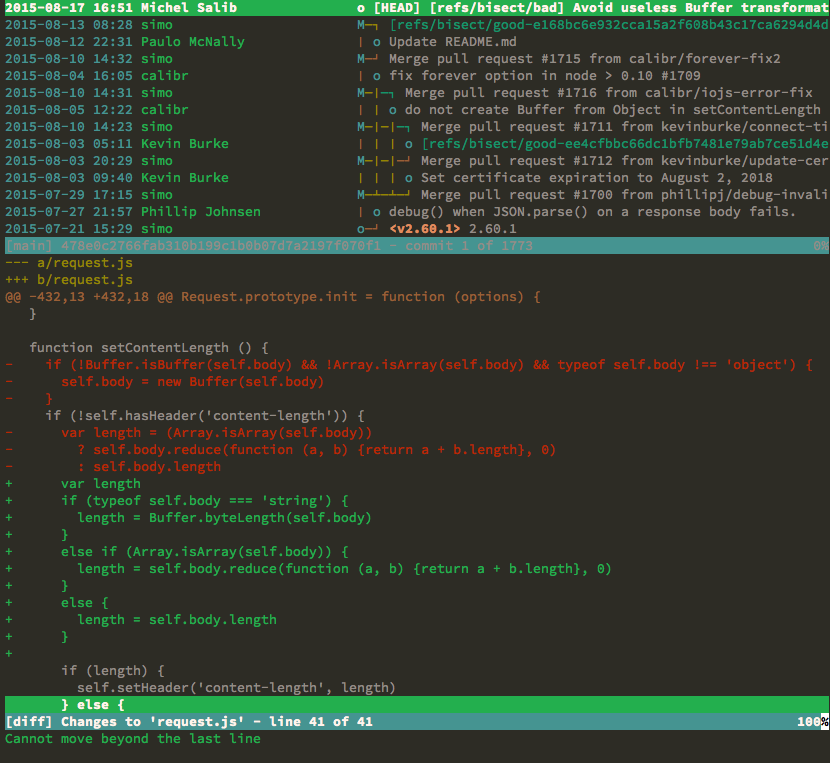
Fortunately, it’s quite small, and the likely cause of the regression jumps out immediately:
self.body = new Buffer(self.body)
It would seem that the request payload object (self.body) would get cast to
Buffer if it was a String before this change. Strings have a larger memory
overhead than Buffers, so it would make sense that in our scenario where we’re
sending many requests with large payloads, using strings instead of Buffers
would cause memory exhaustion faster.
Which is indeed confirmed by the test once we re-add that line back in. Success! :v:
(and PR sent)
Lessons Learned
What can we learn from this?
git-bisectis very neat- Innocuous-looking changes can have unexpected impact on performance
- Pin your dependencies to exact versions in production code.
npm i --save-exactis your friend.